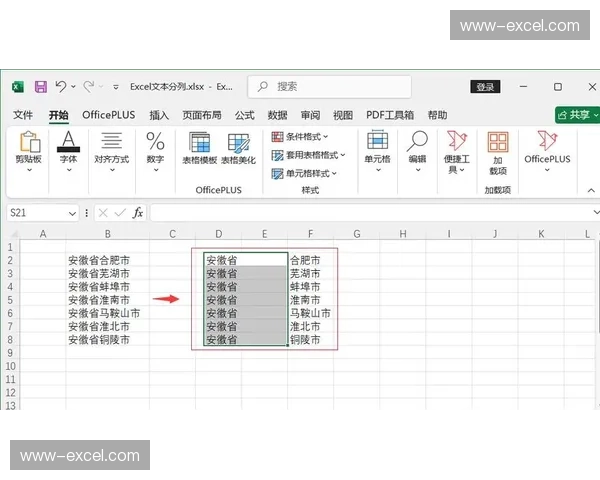
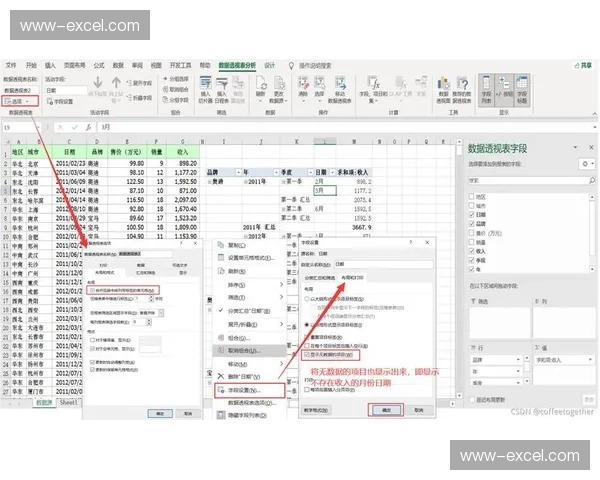
гҖҖгҖҖExcelдҪңдёәеҫ®иҪҜOfficeеҘ—件зҡ„ж ёеҝғ组件пјҢе…¶ж•°жҚ®еӨ„зҗҶиғҪеҠӣдёҖзӣҙжҳҜдјҒдёҡзә§еә”з”Ёзҡ„еҹәзҹігҖӮ然иҖҢпјҢйҡҸзқҖж•°жҚ®йҮҸзҡ„жҝҖеўһе’ҢеҲҶжһҗйңҖжұӮзҡ„еӨҚжқӮеҢ–пјҢдј з»ҹе·ҘдҪңиЎЁзҡ„жҖ§иғҪ瓶йўҲйҖҗжёҗжҳҫзҺ°гҖӮжң¬ж–Үе°Ҷж·ұе…ҘжҺўи®ЁExcelдёӯвҖңж•°жҚ®зұ»еһӢвҖқзҡ„еә•еұӮе®һзҺ°жңәеҲ¶пјҢд»ҘеҸҠеҰӮдҪ•йҖҡиҝҮдјҳеҢ–ж•°жҚ®зұ»еһӢе®ҡд№үжқҘжҸҗеҚҮдә”иЎҢпјҲеҚідә”иЎҢж•°жҚ®ж ЎйӘҢпјүзҡ„ж•ҲзҺҮдёҺеҮҶзЎ®жҖ§гҖӮиҝҷдёҖй—®йўҳдёҚд»…ж¶үеҸҠExcelзҡ„жҠҖжңҜжһ¶жһ„пјҢиҝҳе…ізі»еҲ°ж•°жҚ®еҲҶжһҗзҡ„еҸҜйқ жҖ§дёҺжү©еұ•жҖ§гҖӮ
Excelж•°жҚ®зұ»еһӢзҡ„еә•еұӮе®һзҺ°жңәеҲ¶
гҖҖгҖҖExcelзҡ„ж•°жҚ®зұ»еһӢдҪ“зі»жҳҜе…¶еҠҹиғҪзҡ„ж ёеҝғж”Ҝж’‘пјҢдё»иҰҒеҢ…жӢ¬ж•°еҖјеһӢгҖҒж–Үжң¬еһӢгҖҒж—ҘжңҹеһӢгҖҒйҖ»иҫ‘еһӢзӯүеҹәзЎҖзұ»еһӢпјҢд»ҘеҸҠиҮӘе®ҡд№үзұ»еһӢе’ҢеӨҚжқӮж•°жҚ®з»“жһ„гҖӮиҝҷдәӣзұ»еһӢйҖҡиҝҮеә•еұӮзҡ„COMпјҲ组件еҜ№иұЎжЁЎеһӢпјүжҺҘеҸЈе’ҢOLEпјҲеҜ№иұЎй“ҫжҺҘдёҺеөҢе…ҘпјүжҠҖжңҜе®һзҺ°дәӨдә’гҖӮдҫӢеҰӮпјҢеҪ“з”ЁжҲ·иҫ“е…ҘдёҖдёӘе…¬ејҸж—¶пјҢExcelдјҡж №жҚ®е…¬ејҸзҡ„иҜӯд№үиҮӘеҠЁжҺЁж–ӯж•°жҚ®зұ»еһӢпјҢ并еңЁеҶ…еӯҳдёӯеҲҶй…Қзӣёеә”зҡ„еӯҳеӮЁз©әй—ҙгҖӮиҝҷдёҖиҝҮзЁӢдҫқиө–дәҺExcelзҡ„е…¬ејҸи§Јжһҗеј•ж“ҺпјҲFormula ParserпјүпјҢиҜҘеј•ж“ҺеҹәдәҺеҫ®иҪҜзҡ„и„ҡжң¬еј•ж“ҺпјҲScripting EngineпјүиҝӣиЎҢжү©еұ•гҖӮ
гҖҖгҖҖд»ҺжҠҖжңҜе®һзҺ°зҡ„и§’еәҰзңӢпјҢExcelзҡ„ж•°жҚ®зұ»еһӢеӯҳеӮЁйҮҮз”ЁдәҶдёҖз§ҚеҲҶеұӮз»“жһ„гҖӮеҹәзЎҖж•°жҚ®зұ»еһӢеҰӮж•°еҖјгҖҒж–Үжң¬зӯүеӯҳеӮЁеңЁеҚ•е…ғж јеҜ№иұЎзҡ„CellValueеұһжҖ§дёӯпјҢиҖҢеӨҚжқӮзұ»еһӢеҰӮиЎЁж јгҖҒеӣҫиЎЁзӯүеҲҷйҖҡиҝҮеҜ№иұЎеј•з”ЁпјҲObject ReferenceпјүжңәеҲ¶дёҺдё»ж–ҮжЎЈеҲҶзҰ»гҖӮиҝҷз§Қи®ҫи®ЎдҪҝеҫ—ExcelеңЁеӨ„зҗҶеӨ§еһӢе·ҘдҪңз°ҝж—¶иғҪеӨҹжңүж•Ҳз®ЎзҗҶеҶ…еӯҳгҖӮдҫӢеҰӮпјҢдёҖдёӘеҢ…еҗ«100дёҮиЎҢж•°жҚ®зҡ„е·ҘдҪңиЎЁпјҢе…¶ж•°жҚ®зұ»еһӢе®ҡд№үдёҚдјҡеҚ з”ЁиҝҮеӨҡзҡ„еҶ…еӯҳиө„жәҗпјҢеӣ дёәExcelйҮҮз”ЁдәҶжғ°жҖ§еҠ иҪҪпјҲLazy Loadingпјүзӯ–з•ҘпјҢеҚіеҸӘжңүеңЁз”ЁжҲ·е®һйҷ…и®ҝй—®ж•°жҚ®ж—¶жүҚдјҡеҠ иҪҪе®Ңж•ҙзҡ„ж•°жҚ®зұ»еһӢдҝЎжҒҜгҖӮ
гҖҖгҖҖ然иҖҢпјҢж•°жҚ®зұ»еһӢзҡ„е®һзҺ°е№¶йқһжІЎжңүзјәйҷ·гҖӮж №жҚ®еҫ®иҪҜзҡ„жҠҖжңҜзҷҪзҡ®д№ҰпјҲTechnical White PaperпјүпјҢExcelзҡ„ж•°жҚ®зұ»еһӢжҺЁж–ӯеј•ж“ҺеңЁеӨ„зҗҶи·Ёзұ»еһӢиҝҗз®—ж—¶еӯҳеңЁжҪңеңЁзҡ„зІҫеәҰжҚҹеӨұй—®йўҳгҖӮдҫӢеҰӮпјҢеҪ“дёҖдёӘж•°еҖјеһӢж•°жҚ®дёҺж–Үжң¬еһӢж•°жҚ®иҝӣиЎҢиҝһжҺҘж“ҚдҪңж—¶пјҢExcelдјҡиҮӘеҠЁе°Ҷж•°еҖјиҪ¬жҚўдёәж–Үжң¬пјҢиҝҷдёҖиҝҮзЁӢеҸҜиғҪеҜјиҮҙзІҫеәҰдёўеӨұгҖӮжӯӨеӨ–пјҢExcelзҡ„ж•°жҚ®зұ»еһӢе®ҡд№үеңЁеӨҡз”ЁжҲ·еҚҸдҪңеңәжҷҜдёӢд№ҹйқўдёҙжҢ‘жҲҳпјҢеӣ дёәдёҚеҗҢз”ЁжҲ·зҡ„иҫ“е…ҘеҸҜиғҪеј•е…ҘдёҚдёҖиҮҙзҡ„ж•°жҚ®зұ»еһӢпјҢд»ҺиҖҢеҪұе“Қж•ҙдҪ“ж•°жҚ®зҡ„е®Ңж•ҙжҖ§гҖӮ
гҖҖгҖҖдёәдәҶеә”еҜ№иҝҷдәӣй—®йўҳпјҢExcelеј•е…ҘдәҶж•°жҚ®зұ»еһӢ规иҢғеҢ–пјҲType NormalizationпјүжңәеҲ¶гҖӮиҝҷдёҖжңәеҲ¶йҖҡиҝҮйў„е®ҡд№үзҡ„ж•°жҚ®зұ»еһӢжҳ е°„иЎЁпјҢе°Ҷз”ЁжҲ·иҫ“е…Ҙзҡ„ж•°жҚ®иҪ¬жҚўдёәж ҮеҮҶеҢ–зҡ„зұ»еһӢиЎЁзӨәгҖӮдҫӢеҰӮпјҢз”ЁжҲ·иҫ“е…Ҙзҡ„ж—Ҙжңҹеӯ—з¬ҰдёІдјҡиў«иҪ¬жҚўдёәзі»з»ҹеҶ…йғЁзҡ„datetimeж јејҸпјҢд»ҺиҖҢйҒҝе…Қеӣ ж јејҸдёҚдёҖиҮҙеҜјиҮҙзҡ„и®Ўз®—й”ҷиҜҜгҖӮиҝҷдёҖжңәеҲ¶еңЁExcelзҡ„е…¬ејҸи®Ўз®—дёӯе°ӨдёәйҮҚиҰҒпјҢеӣ дёәе…¬ејҸдҫқиө–дәҺж•°жҚ®зұ»еһӢзҡ„еҮҶзЎ®жҖ§е’ҢдёҖиҮҙжҖ§гҖӮ
гҖҖгҖҖеҖјеҫ—жіЁж„Ҹзҡ„жҳҜпјҢExcelзҡ„ж•°жҚ®зұ»еһӢе®һзҺ°иҝҳеҸ—еҲ°ж“ҚдҪңзі»з»ҹзҡ„еә•еұӮж”ҜжҢҒеҪұе“ҚгҖӮдҫӢеҰӮпјҢеңЁWindowsзі»з»ҹдёӯпјҢExcelзҡ„ж•°жҚ®зұ»еһӢеӯҳеӮЁдёҺжіЁеҶҢиЎЁпјҲRegistryпјүдёӯзҡ„ж•°жҚ®зұ»еһӢе®ҡд№үеҜҶеҲҮзӣёе…ігҖӮиҝҷдҪҝеҫ—ExcelиғҪеӨҹж №жҚ®ж“ҚдҪңзі»з»ҹзҡ„дёҚеҗҢпјҢеҠЁжҖҒи°ғж•ҙе…¶ж•°жҚ®зұ»еһӢеӨ„зҗҶзӯ–з•ҘгҖӮ然иҖҢпјҢиҝҷд№ҹж„Ҹе‘ізқҖеңЁжҹҗдәӣзү№е®ҡзҡ„ж“ҚдҪңзі»з»ҹзҺҜеўғдёӢпјҢExcelзҡ„ж•°жҚ®зұ»еһӢиЎЁзҺ°еҸҜиғҪеӯҳеңЁе·®ејӮгҖӮ
дә”иЎҢж•°жҚ®ж ЎйӘҢзҡ„жҠҖжңҜз»ҶиҠӮ
гҖҖгҖҖдә”иЎҢж•°жҚ®ж ЎйӘҢжҳҜExcelдёӯдёҖйЎ№еҹәзЎҖдҪҶиҮіе…ійҮҚиҰҒзҡ„еҠҹиғҪпјҢе®ғдё»иҰҒз”ЁдәҺзЎ®дҝқж•°жҚ®иҫ“е…Ҙзҡ„еҮҶзЎ®жҖ§е’ҢдёҖиҮҙжҖ§гҖӮиҝҷдёҖеҠҹиғҪзҡ„е®һзҺ°дҫқиө–дәҺExcelзҡ„ж•°жҚ®йӘҢиҜҒ规еҲҷпјҲData Validation RulesпјүпјҢиҝҷдәӣ规еҲҷйҖҡиҝҮе·ҘдҪңиЎЁзҡ„ValidationеұһжҖ§дёҺеҚ•е…ғж је…іиҒ”гҖӮдҫӢеҰӮпјҢз”ЁжҲ·еҸҜд»Ҙи®ҫзҪ®дёҖдёӘеҚ•е…ғж јеҸӘиғҪиҫ“е…Ҙзү№е®ҡиҢғеӣҙеҶ…зҡ„ж•°еҖјпјҢжҲ–иҖ…еҸӘиғҪиҫ“е…Ҙз¬ҰеҗҲзү№е®ҡж јејҸзҡ„ж–Үжң¬гҖӮиҝҷдәӣ规еҲҷзҡ„еә•еұӮе®һзҺ°еҹәдәҺExcelзҡ„规еҲҷеј•ж“ҺпјҲRule EngineпјүпјҢиҜҘеј•ж“ҺйҖҡиҝҮжӯЈеҲҷиЎЁиҫҫејҸпјҲRegular Expressionпјүе’ҢжқЎд»¶еҲӨж–ӯпјҲConditional LogicпјүжқҘжү§иЎҢж ЎйӘҢгҖӮ
гҖҖгҖҖд»Һз®—жі•еұӮйқўзңӢпјҢдә”иЎҢж•°жҚ®ж ЎйӘҢзҡ„ж ёеҝғжҳҜж•°жҚ®зұ»еһӢеҢ№й…ҚдёҺж јејҸйӘҢиҜҒгҖӮдҫӢеҰӮпјҢеҪ“з”ЁжҲ·иҫ“е…ҘдёҖдёӘж–Үжң¬еӯ—з¬ҰдёІж—¶пјҢExcelдјҡйҰ–е…ҲжЈҖжҹҘиҜҘеӯ—з¬ҰдёІжҳҜеҗҰз¬ҰеҗҲйў„е®ҡд№үзҡ„ж•°жҚ®зұ»еһӢ规иҢғгҖӮеҰӮжһңж•°жҚ®зұ»еһӢдёәж•°еҖјеһӢпјҢExcelдјҡе°қиҜ•е°Ҷеӯ—з¬ҰдёІиҪ¬жҚўдёәж•°еҖјпјҢ并еңЁиҪ¬жҚўеӨұиҙҘж—¶и§ҰеҸ‘й”ҷиҜҜжҸҗзӨәгҖӮиҝҷдёҖиҝҮзЁӢдҫқиө–дәҺExcelзҡ„зұ»еһӢиҪ¬жҚўжЁЎеқ—пјҲType Conversion ModuleпјүпјҢиҜҘжЁЎеқ—еҹәдәҺеҫ®иҪҜзҡ„Variantж•°жҚ®зұ»еһӢе®һзҺ°пјҢиғҪеӨҹж”ҜжҢҒеӨҡз§Қж•°жҚ®зұ»еһӢд№Ӣй—ҙзҡ„иҪ¬жҚўгҖӮ
гҖҖгҖҖжӯӨеӨ–пјҢдә”иЎҢж•°жҚ®ж ЎйӘҢиҝҳж¶үеҸҠж•°жҚ®е®Ңж•ҙжҖ§и§„еҲҷзҡ„е®һзҺ°гҖӮдҫӢеҰӮпјҢз”ЁжҲ·еҸҜд»Ҙи®ҫзҪ®ж•°жҚ®жңүж•ҲжҖ§и§„еҲҷпјҢйҷҗеҲ¶еҚ•е…ғж јеҸӘиғҪеј•з”Ёзү№е®ҡиҢғеӣҙеҶ…зҡ„ж•°жҚ®гҖӮиҝҷдёҖеҠҹиғҪйҖҡиҝҮExcelзҡ„иҢғеӣҙеҜ№иұЎпјҲRange Objectпјүе’Ңеј•з”Ёи§ЈжһҗеҷЁпјҲReference Resolverпјүе®һзҺ°гҖӮеҪ“з”ЁжҲ·иҫ“е…Ҙж•°жҚ®ж—¶пјҢExcelдјҡи§ЈжһҗиҜҘж•°жҚ®жҳҜеҗҰз¬ҰеҗҲйў„и®ҫзҡ„引用规еҲҷпјҢ并еңЁдёҚз¬ҰеҗҲж—¶йҳ»жӯўж•°жҚ®зҡ„иҫ“е…ҘгҖӮиҝҷдёҖжңәеҲ¶еңЁеӨ§еһӢж•°жҚ®иЎЁдёӯе°ӨдёәйҮҚиҰҒпјҢеӣ дёәе®ғиғҪеӨҹжңүж•ҲйҳІжӯўж•°жҚ®еј•з”Ёй”ҷиҜҜгҖӮ
гҖҖгҖҖд»ҺжҖ§иғҪи§’еәҰжқҘзңӢпјҢдә”иЎҢж•°жҚ®ж ЎйӘҢзҡ„е®һзҺ°йңҖиҰҒжқғиЎЎе®һж—¶жҖ§дёҺиө„жәҗж¶ҲиҖ—гҖӮExcelйҮҮз”ЁдәҶдёҖз§ҚеўһйҮҸејҸж ЎйӘҢпјҲIncremental Validationпјүзӯ–з•ҘпјҢеҚіеҸӘжңүеңЁз”ЁжҲ·е®ҢжҲҗж•°жҚ®иҫ“е…ҘжҲ–зҰ»ејҖеҚ•е…ғж јж—¶жүҚдјҡи§ҰеҸ‘ж ЎйӘҢгҖӮиҝҷдёҖзӯ–з•ҘиғҪеӨҹжңүж•ҲеҮҸе°‘ж ЎйӘҢеҜ№зі»з»ҹиө„жәҗзҡ„еҚ з”ЁпјҢдҪҶд№ҹеҸҜиғҪеҜјиҮҙз”ЁжҲ·еңЁиҫ“е…ҘиҝҮзЁӢдёӯж— жі•еҚіж—¶иҺ·еҸ–еҸҚйҰҲгҖӮдёәдәҶдјҳеҢ–иҝҷдёҖй—®йўҳпјҢExcelеј•е…ҘдәҶж ЎйӘҢзј“еӯҳпјҲValidation CacheпјүжңәеҲ¶пјҢе°Ҷйў‘з№Ғж ЎйӘҢзҡ„з»“жһңеӯҳеӮЁеңЁеҶ…еӯҳдёӯпјҢд»ҺиҖҢеҮҸе°‘йҮҚеӨҚж ЎйӘҢеёҰжқҘзҡ„жҖ§иғҪејҖй”ҖгҖӮ
гҖҖгҖҖеңЁе®һйҷ…еә”з”ЁдёӯпјҢдә”иЎҢж•°жҚ®ж ЎйӘҢзҡ„е®һзҺ°иҝҳйқўдёҙдёҖдәӣжҢ‘жҲҳгҖӮдҫӢеҰӮпјҢеҪ“ж•°жҚ®иЎЁеҢ…еҗ«еӨ§йҮҸеӨҚжқӮ规еҲҷж—¶пјҢж ЎйӘҢиҝҮзЁӢеҸҜиғҪдјҡеҸҳеҫ—зј“ж…ўпјҢе°Өе…¶жҳҜеңЁзҪ‘з»ңзҺҜеўғдёӯпјҢж•°жҚ®ж ЎйӘҢзҡ„延иҝҹеҸҜиғҪеҪұе“Қз”ЁжҲ·дҪ“йӘҢгҖӮдёәдәҶи§ЈеҶіиҝҷдёҖй—®йўҳпјҢExcelж”ҜжҢҒеҲҶеёғејҸж ЎйӘҢпјҲDistributed ValidationпјүпјҢеҚіе°Ҷж ЎйӘҢд»»еҠЎеҲҶй…ҚеҲ°еӨҡдёӘе·ҘдҪңиҝӣзЁӢпјҲWorker Processпјүдёӯ并иЎҢеӨ„зҗҶгҖӮиҝҷдёҖжңәеҲ¶еңЁеӨ§еһӢдјҒдёҡзә§еә”з”Ёдёӯе°Өдёәжңүж•ҲпјҢиғҪеӨҹжҳҫи‘—жҸҗеҚҮж•°жҚ®ж ЎйӘҢзҡ„ж•ҲзҺҮгҖӮ
гҖҖгҖҖжӯӨеӨ–пјҢдә”иЎҢж•°жҚ®ж ЎйӘҢзҡ„е®һзҺ°иҝҳж¶үеҸҠдёҺеӨ–йғЁзі»з»ҹзҡ„йӣҶжҲҗгҖӮдҫӢеҰӮпјҢеҪ“Excelж–Ү件被еҜје…ҘеҲ°ж•°жҚ®еә“зі»з»ҹж—¶пјҢж•°жҚ®ж ЎйӘҢ规еҲҷйңҖиҰҒдёҺж•°жҚ®еә“зҡ„зәҰжқҹпјҲConstraintпјүиҝӣиЎҢеҗҢжӯҘгҖӮиҝҷдёҖиҝҮзЁӢдҫқиө–дәҺExcelзҡ„ж•°жҚ®е®ҡд№үиҜӯиЁҖпјҲData Definition Language, DDLпјүпјҢйҖҡиҝҮExcelзҡ„XMLеҜјеҮәеҠҹиғҪз”ҹжҲҗз¬ҰеҗҲж•°жҚ®еә“ж ҮеҮҶзҡ„ж•°жҚ®е®ҡд№үж–Ү件гҖӮиҝҷдёҖжңәеҲ¶дҪҝеҫ—Excelзҡ„ж•°жҚ®ж ЎйӘҢеҠҹиғҪиғҪеӨҹдёҺдјҒдёҡзә§ж•°жҚ®з®ЎзҗҶзі»з»ҹж— зјқйӣҶжҲҗгҖӮ
гҖҖгҖҖеҖјеҫ—дёҖжҸҗзҡ„жҳҜпјҢдә”иЎҢж•°жҚ®ж ЎйӘҢзҡ„е®һзҺ°иҝҳеҸ—еҲ°ExcelзүҲжң¬зҡ„еҪұе“ҚгҖӮиҫғж—§зүҲжң¬зҡ„ExcelпјҲеҰӮExcel 2003пјүеңЁж•°жҚ®зұ»еһӢеӨ„зҗҶдёҠеӯҳеңЁдёҖе®ҡзҡ„еұҖйҷҗжҖ§пјҢдҫӢеҰӮпјҢеҜ№иҮӘе®ҡд№үж•°жҚ®зұ»еһӢзҡ„ж”ҜжҢҒиҫғдёәжңүйҷҗгҖӮиҖҢжӣҙж–°зүҲжң¬пјҲеҰӮExcel 2016еҸҠд»ҘеҗҺпјүеҲҷеј•е…ҘдәҶжӣҙзҒөжҙ»зҡ„ж•°жҚ®зұ»еһӢе®ҡд№үжңәеҲ¶пјҢдҫӢеҰӮж”ҜжҢҒJSONж јејҸзҡ„ж•°жҚ®зұ»еһӢе®ҡд№үгҖӮиҝҷдёҖж”№иҝӣдҪҝеҫ—ExcelиғҪеӨҹжӣҙеҘҪең°йҖӮеә”зҺ°д»Јж•°жҚ®еӨ„зҗҶзҡ„йңҖжұӮгҖӮ
гҖҖгҖҖйҡҸзқҖж•°жҚ®еҲҶжһҗйңҖжұӮзҡ„дёҚж–ӯеўһй•ҝпјҢExcelзҡ„ж•°жҚ®зұ»еһӢдјҳеҢ–жҲҗдёәжҸҗеҚҮжҖ§иғҪзҡ„е…ій”®ж–№еҗ‘гҖӮдј з»ҹзҡ„ж•°жҚ®зұ»еһӢе®ҡд№үж–№ејҸеңЁйқўеҜ№еӨ§и§„жЁЎж•°жҚ®ж—¶иЎЁзҺ°дёҚдҪіпјҢеӣ жӯӨпјҢеҫ®иҪҜиҝ‘е№ҙжқҘеј•е…ҘдәҶзұ»еһӢзі»з»ҹжү©еұ•пјҲType System ExtensionпјүжңәеҲ¶гҖӮиҝҷдёҖжңәеҲ¶е…Ғи®ёејҖеҸ‘дәәе‘ҳйҖҡиҝҮиҮӘе®ҡд№үзұ»еһӢе®ҡд№үпјҲCustom Type DefinitionпјүжқҘжү©еұ•Excelзҡ„еҶ…зҪ®ж•°жҚ®зұ»еһӢгҖӮexcel下载дҫӢеҰӮпјҢз”ЁжҲ·еҸҜд»Ҙе®ҡд№үдёҖдёӘж–°зҡ„ж•°жҚ®зұ»еһӢжқҘиЎЁзӨәзү№е®ҡиЎҢдёҡзҡ„дё“дёҡжңҜиҜӯпјҢд»ҺиҖҢжҸҗеҚҮж•°жҚ®еҲҶжһҗзҡ„еҮҶзЎ®жҖ§гҖӮ

гҖҖгҖҖд»ҺжҠҖжңҜжһ¶жһ„зҡ„и§’еәҰзңӢпјҢж•°жҚ®зұ»еһӢдјҳеҢ–зҡ„ж ёеҝғеңЁдәҺеҮҸе°‘ж•°жҚ®иҪ¬жҚўзҡ„ејҖй”ҖгҖӮExcelйҖҡиҝҮеј•е…Ҙзұ»еһӢж„ҹзҹҘзј–зЁӢпјҲType-Driven ProgrammingпјүжЁЎеһӢпјҢдҪҝеҫ—ејҖеҸ‘дәәе‘ҳиғҪеӨҹеңЁд»Јз ҒеұӮйқўжӣҙзІҫзЎ®ең°жҺ§еҲ¶ж•°жҚ®зұ»еһӢгҖӮдҫӢеҰӮпјҢдҪҝз”ЁVBAпјҲVisual Basic for ApplicationsпјүејҖеҸ‘зҡ„е®ҸеҸҜд»ҘжҢҮе®ҡж•°жҚ®зұ»еһӢзҡ„зІҫзЎ®иҢғеӣҙпјҢд»ҺиҖҢеҮҸе°‘иҝҗиЎҢж—¶зҡ„зұ»еһӢиҪ¬жҚўгҖӮиҝҷдёҖдјҳеҢ–зӯ–з•ҘеңЁдјҒдёҡзә§еә”з”Ёдёӯе°ӨдёәйҮҚиҰҒпјҢеӣ дёәе®ғиғҪеӨҹжҳҫи‘—жҸҗеҚҮж•°жҚ®еӨ„зҗҶзҡ„ж•ҲзҺҮгҖӮ
гҖҖгҖҖжңӘжқҘпјҢExcelзҡ„ж•°жҚ®зұ»еһӢеӨ„зҗҶеҸҜиғҪдјҡжңқзқҖжӣҙеҠ жҷәиғҪеҢ–зҡ„ж–№еҗ‘еҸ‘еұ•гҖӮж №жҚ®еҫ®иҪҜзҡ„жҠҖжңҜи·ҜзәҝеӣҫпјҲTechnical RoadmapпјүпјҢжңӘжқҘзҡ„ExcelзүҲжң¬еҸҜиғҪдјҡеј•е…Ҙдәәе·ҘжҷәиғҪпјҲAIпјүй©ұеҠЁзҡ„ж•°жҚ®зұ»еһӢжҺЁж–ӯгҖӮдҫӢеҰӮпјҢзі»з»ҹе°ҶиғҪеӨҹж №жҚ®еҺҶеҸІж•°жҚ®иҮӘеҠЁиҜҶеҲ«жңҖдҪізҡ„ж•°жҚ®зұ»еһӢе®ҡд№үпјҢд»ҺиҖҢеҮҸе°‘з”ЁжҲ·зҡ„жүӢеҠЁй…ҚзҪ®гҖӮиҝҷдёҖеҠҹиғҪе°ҶжһҒеӨ§жҸҗеҚҮж•°жҚ®еӨ„зҗҶзҡ„иҮӘеҠЁеҢ–ж°ҙе№іпјҢдҪҶд№ҹеҜ№Excelзҡ„еә•еұӮз®—жі•жҸҗеҮәдәҶжӣҙй«ҳзҡ„иҰҒжұӮгҖӮ
гҖҖгҖҖжӯӨеӨ–пјҢж•°жҚ®зұ»еһӢзҡ„жңӘжқҘеҸ‘еұ•и¶ӢеҠҝиҝҳеҢ…жӢ¬дёҺж–°е…ҙжҠҖжңҜзҡ„иһҚеҗҲгҖӮдҫӢеҰӮпјҢйҡҸзқҖдә‘и®Ўз®—зҡ„жҷ®еҸҠпјҢExcelзҡ„ж•°жҚ®зұ»еһӢе®ҡд№үеҸҜиғҪдјҡдёҺдә‘еӯҳеӮЁжңҚеҠЎпјҲеҰӮAzureпјүж·ұеәҰйӣҶжҲҗгҖӮиҝҷж„Ҹе‘ізқҖж•°жҚ®зұ»еһӢдҝЎжҒҜе°Ҷиў«еӯҳеӮЁеңЁдә‘з«ҜпјҢе№¶ж №жҚ®дёҚеҗҢзҡ„е®ўжҲ·з«ҜзҺҜеўғеҠЁжҖҒи°ғж•ҙгҖӮиҝҷдёҖеҸҳйқ©е°ҶдҪҝеҫ—ExcelиғҪеӨҹжӣҙеҘҪең°йҖӮеә”еӨҡж ·еҢ–зҡ„дҪҝз”ЁеңәжҷҜпјҢеҗҢж—¶жҸҗеҚҮж•°жҚ®зҡ„дёҖиҮҙжҖ§гҖӮ
гҖҖгҖҖеңЁе®үе…ЁжҖ§ж–№йқўпјҢж•°жҚ®зұ»еһӢдјҳеҢ–д№ҹйқўдёҙж–°зҡ„жҢ‘жҲҳгҖӮйҡҸзқҖж•°жҚ®йҡҗз§Ғ法规пјҲеҰӮGDPRпјүзҡ„е®һж–ҪпјҢExcelйңҖиҰҒзЎ®дҝқж•°жҚ®зұ»еһӢзҡ„е®ҡд№үдёҚдјҡеҜјиҮҙж•Ҹж„ҹдҝЎжҒҜзҡ„жі„йңІгҖӮдёәжӯӨпјҢеҫ®иҪҜжӯЈеңЁејҖеҸ‘еҹәдәҺеҢәеқ—й“ҫпјҲBlockchainпјүзҡ„ж•°жҚ®зұ»еһӢеҠ еҜҶжңәеҲ¶пјҢиҝҷдёҖжңәеҲ¶иғҪеӨҹзЎ®дҝқж•°жҚ®зұ»еһӢзҡ„е®ҡд№үеңЁдј иҫ“е’ҢеӯҳеӮЁиҝҮзЁӢдёӯдёҚдјҡиў«зҜЎж”№гҖӮ
гҖҖгҖҖжңҖеҗҺпјҢж•°жҚ®зұ»еһӢдјҳеҢ–дёҚд»…д»…жҳҜжҠҖжңҜй—®йўҳпјҢиҝҳж¶үеҸҠз”ЁжҲ·дҪ“йӘҢзҡ„и®ҫи®ЎгҖӮдҫӢеҰӮпјҢExcelжӯЈеңЁжҺўзҙўйҖҡиҝҮеҸҜи§ҶеҢ–зҡ„ж–№ејҸеұ•зӨәж•°жҚ®зұ»еһӢзҡ„е®ҡд№үпјҢдҪҝз”ЁжҲ·иғҪеӨҹжӣҙзӣҙи§Ӯең°зҗҶи§Јж•°жҚ®зұ»еһӢдёҺж•°жҚ®д№Ӣй—ҙзҡ„е…ізі»гҖӮиҝҷдёҖж”№иҝӣе°Ҷеё®еҠ©з”ЁжҲ·жӣҙй«ҳж•Ҳең°иҝӣиЎҢж•°жҚ®з®ЎзҗҶпјҢеҗҢж—¶еҮҸе°‘еӣ ж•°жҚ®зұ»еһӢй”ҷиҜҜеҜјиҮҙзҡ„еҲҶжһҗеҒҸе·®гҖӮ
Excelзҡ„ж•°жҚ®зұ»еһӢе®һзҺ°е’Ңдә”иЎҢж•°жҚ®ж ЎйӘҢжҳҜе…¶ж ёеҝғеҠҹиғҪзҡ„йҮҚиҰҒз»„жҲҗйғЁеҲҶгҖӮйҖҡиҝҮж·ұе…ҘзҗҶи§ЈиҝҷдәӣжҠҖжңҜз»ҶиҠӮпјҢжҲ‘们еҸҜд»ҘжӣҙеҘҪең°еҲ©з”ЁExcelиҝӣиЎҢж•°жҚ®еҲҶжһҗпјҢеҗҢж—¶дёәжңӘжқҘзҡ„жҠҖжңҜеҚҮзә§жҸҗдҫӣж–№еҗ‘гҖӮ